
In this post, I want to explain how to architecting ASP.NET Core applications for enterprise projects based on clean architecture principles. In particular, I want to write this as an extension of how to create a digital transformation in your company. First, for architecting ASP.NET Core Applications we have to learn:
- Clean architecture with ASP.NET Core
- Best practices
- Common packages
- Testable and maintainable
The source code of this post is on GitHub. Because one single post is too long, I have created the following posts:
- Architecting ASP.NET Core applications
- Setting up the application core
- Introducing CQRS in the architecture
- Adding Validation using Fluent
- Creating the infrastructure project
- Adding an API using ASP.NET Core
- How testing the application code
- How adding an UI built in Blazor
- Improving on the application’s behaviour
Understanding foundational architectural principles
So, understanding some of the most foundational architectural principles is, of course, key to building a good architecture for our application. Making sure that we’re all on the same page in terms of understanding some of the most key concepts when building a software architecture is really my goal for this section.
Now, let’s us start by taking a look at what exactly we will be covering here. First, we will look together at some of the base principles that will come into play throughout the entire architecture. If you have been writing software for some time, this will probably sound familiar, but just to be sure we’re talking about the same things here, I’m going to go over these without going in too much depth here. Next, I will explain the different commonly used application architecture styles, and then we will explore the concept of clean architecture, which we will be using to build the application architecture for MyTicket upon. Let’s dive in.
Foundational Architectural Principles
Now, as said, we’ll start the post with an overview of some of the foundational architectural principles that are key to understanding the design choices for our application. Which principles do I want to cover here, then? We’ll look at dependency inversion, separation of concerns, single responsibility, the DRY, or don’t repeat yourself principle, and persistence ignorance. This should be merely a refresher for these topics, but we will be referring to these and using them throughout the entire course while creating our architecture. So, let’s start by looking at dependency inversion, one of the SOLID principles. Indeed, dependency inversion is the D in SOLID.
Dependency inversion (DI)
Dependency inversion will help us with decoupling different modules within our application. Creating loose coupling is one of the key aspects to creating maintainable and easy‑to‑test software. To apply dependency inversion, we’re going to introduce abstractions, typically interfaces.
Normally, dependencies between these different classes go from top to bottom, so from high‑level components that contain the business logic to the implementation components. But to create dependencies between these components, it’s difficult to swap these and, hence, also difficult to test later on. Once we introduce abstractions to decouple the different components, this problem will be solved and we’ll get more loosely coupled components.
Thus, dependencies should be pointing to the abstractions, not to the details. Take a look at an example here. When we write code, typically we will have a number of classes. A depends on B, and B, in turn, depends on C. To use B and C, we’ll introduce a reference from the one class to the next; hence, we are creating a tight coupling at compile time. When running this code, A will always use B, and B will always use C. Testing the code, for example in A, becomes more difficult because it’s tightly linked to the code in B.

Now, what if we introduce dependency inversion here? What I’ve now changed is that we now have an Interface B, which is implemented by Class B, and, similarly, I’ve also introduced an Interface C and a Class C. Though, when writing the code in A, we are now using the abstraction, so the Interface B, thus creating loose coupling. It’s important to understand that both the high level, so the Class A, and the low level, Class B, depends on the same interface, and that’s the abstraction. Hence, we are inverting the normal dependency direction. At runtime, the concrete implementations of Class B is used and the normal flow is still used, but different implementations of Interface B can now be used, and, thus, the code is loosely coupled and can be tested much more easily.
Separation of concerns (SoC)
So, separation of concerns is another key principle, and I assume you already have heard of or are already, hopefully, applying today. Separation of concerns is also part of the SOLID principles. This time it’s the S we’re talking about. At its core, it states that we need to write our applications split up in different blocks of functionality, each covering a separate concern. A concern can really be anything, but each block should just be doing one single job. Don’t write your code in large chunks of code that do everything from, for example, going to the database on one line and on the next line updating the UI.
However, applying separation of concerns, or SoC for short, leads to more componentized, more modular code. Each module will do one single task, and, therefore, it encapsulates all logic for that functionality entirely. For anything else, it will use a different module.
So, a good example is a logging component. When we write our application, we don’t want to include code that does the logging in each and every component. Now, instead we used a logging component which knows how to do logging. Other components will use the logging component for all their logging needs, really.
Then, we have separated out the logging concern. When writing a typical layered architecture, each layer is also basically applying separation of concerns. We are separating the UI from the code that contains the business logic, and that, in turn, is separate from the code that contains the database access logic. Separating out concerns into different components also makes the code more maintainable, another key concept we’re after for our architecture. Quite closely related is single responsibility.
Single responsability
Single responsibility is a term we know from object orientation, which states that a class should just have one responsibility, which is the single reason to change it. Anything else should go in a new class. This single responsibility is encapsulated entirely by this class. Also, applying this pattern leads to more modular systems. We are adding more smaller classes instead of constantly adding functionality to existing ones. Since we don’t change existing classes, we’ll less often break existing functionality.
Now, we can bring this OO principle also to the level of application architecture. Think again of a layered architecture, so with a UI layer, a business logic layer, and a data access layer. Each of these layers should be responsible for just one part of the functionality of the system. The UI layer is entirely responsible for the presentation of the application, while working with the data persistence system is entirely up to the data access layer. Next in the architecting ASP.NET Core Applications is DRY: let’s go.
DRY principle
The DRY principle is another important one. If you’ve never heard of it, you may be thinking, should I be drying off my code? Of course not. It’s an abbreviation for don’t repeat yourself. Applying DRY is something I really hope you’re doing all the time in your current projects, even if you don’t really know that you’re doing it. It states that you shouldn’t be repeating code to cover a specific functionality throughout your application.
So, if you’re doing the same thing in multiple places, you’re bound to make errors since you need to make the change in multiple places instead of just one. Less or even better, no duplicated code at all and, thus, encapsulating a certain functionality and specific component makes your code easier to change and will end up giving you less errors.
Persistence ignorance
Now, another principle that will apply in our application is persistence ignorance. We will see later that we are creating our domain entirely with POCOs, aka plain old CLR objects. Ensuring that these domain classes are not influenced at all by the technology used to persist them is exactly what this principle is stating.
This way, the domain we are modelling with our classes shouldn’t be influenced by the technology. In our case, that will be Entity Framework Core. So, you shouldn’t clutter the domain classes with things like base classes that you need to inherit from or attributes that you need to apply on the properties. Applying this principle correctly ensures that the code isn’t linked to any technology and gives you the freedom to store the entities wherever you want.
You may be thinking I’ve rarely seen a project where we decided to switch database technologies. While it happens, it might be rare, but applying persistence ignorance can also be useful to store your entities, first in the cache and then in the database. It basically doesn’t matter where you store them, they’re just plain objects.
While, like I said, I’m not going to go deep into these patterns, this short refresher should give you enough understanding to follow along with the rest of the course. My main reason to include them here is that we’ll be applying this heavily in our architecture. And don’t worry where we use them. I’ll show you how and why we are doing so.
Different types of application architecture
So, with these principles out of the way, we’re now ready to tackle the next topic, and that is understanding the commonly used application architecture styles. For our application that we’ll start building in the next module, we’ll be basing ourselves on the principles of clean architecture, and before we look at clean architecture, I would like to start with showing you the different styles that you’ll often see and probably have used already in your professional life.
All‑in‑one architecture
The first one is what is often referred to as all‑in‑one architecture. In an all‑in‑one architecture, literally all the code for the application lives in a single project. This could be an ASP.NET Core MVC application, for example, where all the code for the entire application is contained in one single project. This type of application is often the result of starting for a small project using File > New Project, and the team starting to build screens and functionality and to be quick all was placed in a single project. But we all know how things go in software development. The application grows. Hey, add this functionality, please, and before you know it, the entire organization is running on what was once a small application. In essence, there’s nothing really wrong with this approach.
Even in a single project, you can still create layers through folders. But, problems will arise along the way since you will end up with a lot of classes. Now think back to that MVC application. You’ll have lots of model classes, lots of controllers, lots of view models, and so on. And indeed, your models will go in a model folder, and the controllers will go in a controllers folder, so you’re essentially applying layering using folders. But, nothing is stopping you from putting a controller in a models folder, so it’s hard to enforce separation of concerns in the code. And with many files in the same project, the maintainability will also go down dramatically. So I said, while this works, I think it’s hardly the way you want to create a maintainable enterprise application with.
Layered architecture
The second type I want to touch on here is the layered architecture, one I’m sure you’re familiar with. Nearly every application is applying layering in some form or the other, which is, of course, good news. A typical layered architecture will essentially enforce splitting up the code over different blocks, typically different projects in your Visual Studio solution.
This code is really split up according to its task, its concern, and so layering is really pushing through separation of concerns, which we looked at already before. Because we’re splitting the code in different blocks, we’re also applying the DRY principle here. We’re going to try to write a certain functionality once, and if it’s needed from multiple places in our application, we can actually reuse it. We are putting all the code that interacts with the database in the data access layer, and the business logic layer that lives above will use that same code.
Code reuse is a great step and a good direction. We’ll have the code in one place, and we can reuse it if needed. If we need to change it, we also need to change it in just one location. That, in turn, helps with maintainability. If we need to change something that is used from multiple places, we only need to do so in a single location, resulting in less errors, at least hopefully.
Because we applied the separation of concerns too, the code’s maintainability will also increase. It’s easy to find something, and since a certain component is just doing one single functionality, it’ll help not breaking other parts of the application. Finally, layering also brings better pluggability. Assume that we need to switch databases for the project. Through layering, the impact of this change would be limited to just the data access layer. So that’s all good news. Here’s a schema of a typical layered architecture.
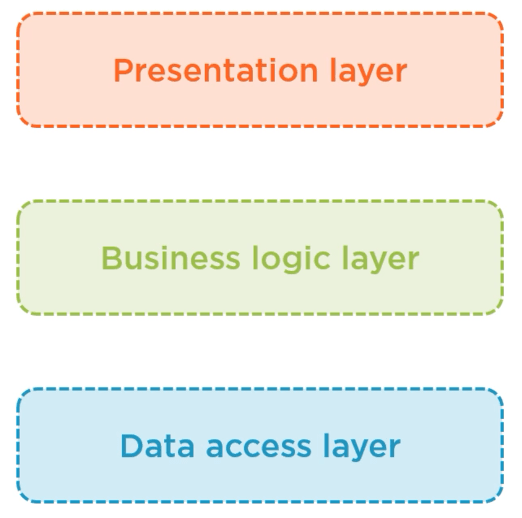
At the top we have the presentation layer, which is concerned with interacting with the user and presenting data to that user. That layer will interact with the business logic layer, also known as the service layer. This is the layer that is agnostic to data persistence code, but will contain things such as the business rules, validations, and the like. Finally, the business layer will interact with the data access layer or the persistence layer. This layer contains your database code, so perhaps if you’re using Entity Framework Core, that will live in here, as well as repositories.
In short, layered architecture helps you to:
- Split according to concern
- Promote reuse
- Easier to maintain
- Pluggable
Disadvantages of layered architecture
There is, to be clear, nothing wrong with this approach. It has been used for many, many applications, and it works fine. But layering also has its disadvantages. For one, although we split up things in separate blocks, these blocks are still, well, dependent on each other.
The business logic layer will have a dependency on the data access layer. So, while we have applied separation of concerns, I’m still concerned, pun intended, that we still end up with coupled layers. And while that is not a horrible thing, it’s possible to do better. And yes, in the end, the code still behaves as a single application. What I mean is that it’s hard to split it up, for example, over multiple servers. Now, that shouldn’t be a big issue here since we are, in fact, looking to create a monolithic application. But, just keep in mind that layering is not going to solve that. If you want to split up your application over multiple environments, giving you the ability to scale parts independently, you need to go the microservices route. That’s not part of what I’m covering here, so let’s not get distracted.
Understand clean architecture
Now that we have revisited other commonly used approaches, the next step is understanding clean architecture. As said, what we’re going to use for the application architecture we’re going to create for MyTicket is clean architecture.
I have been using clean architecture for quite some time for my application development with customers, and I see great results with it. So, let me explain why I think this is a great architecture to use for your next project, too. Clean architecture is an architectural style that is heavily based on the design principles we’ve already looked at.
Basically, applying all these principles correctly will almost immediately bring us to clean architecture, and you’ll see, indeed, that these principles will keep popping up all over the place. Using clean architecture is not really difficult. Like I said, it’s going to boil down to using these principles correctly.
Clean architecture brings a way of structuring the application so that the business object is encapsulated at the heart of the application, making it independent from implementation details. If you followed along, this should ring a bell already. Yes, this has dependency inversion written all over it. Now, clean architecture is really nothing new. It was already introduced in 2012 and is in itself also another reinvention of the wheel. It’s actually a variation of other types of architecture you may have heard of before, namely hexagonal or onion architecture. There are differences between clean and onion and hexagonal architecture design. But I don’t want to go the full theoretical route, I want to start building the application architecture, which we’ll do very soon.
Deep dive clean architecture
Clean architecture is trying to give us the best in terms of testable, maintainable, and scalable code. One of its key features is that it’s based heavily on separation of concerns, most of them plain layered architecture. Remember that I said that although we have layers, they were still referencing each other. Well, that problem will go away with clean architecture.
This will be possible because in clean architecture, things are also based around dependency inversion. Indeed, we’ll use abstractions and the core, so the business logic, will be entirely independent of the UI or of the database code. There won’t even be references to these projects.

Well, closely related to onion architecture, clean architecture also is based around concentric circles. Here, you can see a schema that represents clean architecture, which is, as said, composed out of circles. Each circle contains a layer.
The clean architecture explained
To explore how the code will be structured with clean architecture, we need to start in the middle and work towards the outside of the circles. In the middle, we’ll find the core, which contains abstractions and the domain entities.
Around the entities, we’ll find the application logic, so the services which work on the entities, and it’s also considered part of the core. One very important aspect is that the core is completely agnostic to any other circles that lie around it. That means that the core has completely no knowledge of any implementation details or mechanisms, such as knowing how the data is stored.

The latter, so the implementation mechanisms, live in the infrastructure project or projects, but now take a look at the arrows here, which represent dependencies. They point inwards, so towards the abstraction.
Remember, this is exactly what dependency inversion is all about. In the core, we’re working with abstractions for pretty much everything. Some abstractions are still satisfied within the core, so in the domain services, but most of them will be fulfilled or plugged in from the outside. This is different from traditional layered architecture where the business logic points to the infrastructure layer. Finally, we also have the UI, the user interface, which is also an outer circle. Nothing in the core knows anything about how the data is represented for the user, so this is clean architecture in a nutshell.
Summarize quickly
To summarize, clean architecture is a concentric model where the layers are different circles. At the very center we have the domain entities and interfaces. Still part of what is considered the core, we have the business logic and the application logic. This layer knows absolutely nothing about the implementation details. So when we translate this to a Visual Studio project, there won’t be any references to packages that have anything to do with things like data persistence or logging.
The latter belongs in the next circle, which is the infrastructure layer. This contains the mechanisms, the implementations, for the abstractions defined in the core, it has a dependency on the core.
Finally, we have the UI circle, which is also dependent on the core, so there, too, we’ll have a reference to the core project. To be able to create this type of architecture, there will be two principles which are utterly important. I’ve already mentioned dependency inversion, which will be used heavily.
At runtime, the dependencies defined in the core will be plugged in from other layers. But to keep things, of course, testable, we’ll need to create these abstractions, and when we want to test, we can plug in a different test implementation.
Secondly, and we haven’t touched on this yet, is the mediator pattern. At its core, the mediator will also help us quite a lot to achieve a high level of loose coupling through enabling messaging between different objects instead of creating tightly coupled objects. You may be in your head already trying to map this to a regular layered architecture, and I think that’s a great idea. Let me help you a bit by giving you some more info on what code will now, in clean architecture, go where exactly.
What code where
So what do we place in the core project? Well, entities. So, the domain definitely is part of what we refer to as the core. Secondly, contracts or interfaces or abstractions. They go in there, too. You’ll see soon that we’ll have contracts in there that will be implemented in the core, as well as in the infrastructure.
It is common to have quite a few abstractions in your core project, and you’ll see we’ll also have exceptions, so custom exceptions in here. Now, one thing I want to repeat here is that you should never have any code nor dependencies in the core projects on anything infrastructure related.
So, you shouldn’t have any Entity Framework Core code in your application, nor any logging code, and so on. The latter should actually go in the infrastructure layer. In here, we’ll add implementations for contracts defined in the core project. So if we write in the core that want to save something inside the core, it will basically stop there. We don’t include how it must be saved.
Infrastructure layer
The actual implementation goes in the infrastructure layer. Data access code, so for example Entity Framework Core code, will live here. So will the logging implementation. So, how do we log. Clients for other APIs, which again are also infrastructure code, should also be placed in the infrastructure project, just like anything that has to do with identity or file access.
UI
Finally, what goes in the UI layer then? Well, I guess this one is pretty straightforward. I call it UI, but it can also be an API. We’ll be starting in the next project to create an ASP.NET Core API, but all principles will work fine for MVC or a Razor Pages application as well. Specific ASP.NET Core code should also be part of this layer, and that includes, for example, custom middleware or filters. They don’t belong in the core since they are dependent on ASP.NET Core itself.
Of course, the UI layer will need to interact with the rest of the code. In a layered architecture, the UI goes to the business logic layer. In clean architecture, the UI will communicate with the core project. But I can already say I want to have this communication to be as loosely coupled as possible; therefore, we’ll introduce MediatR and the mediator pattern. But this will result also in very lightweight controller actions, which I also think is good design. Now that you already have an understanding of clean architecture, some of its benefits will start becoming visible too. Writing code this way will make it so that your code is independent of the UI or used frameworks.
How to implement
We can focus our attention on writing the business logic. The code is entirely decoupled from the database that we’re using. Remember that we earlier said we’d like to have persistence ignorance? Well, here you go. And the end result will be a much more maintainable code base. We’ll have a good structure and a solid architectures that can cope with changes. Since it will be easy to run tests for this code because of separation of concerns, we’ll be able to make changes with confidence. Later in the course, I’ll prove that the different layers are actually easy to test in isolation, as well as together through unit tests and integration tests. Just as a glimpse in the not‑so‑distant future, this is what we’ll be working towards. This is how I will be organizing the code. You’ll see that we have a core folder with several projects in there.
Next we’ll have the Infrastructure folder, which contains identity, as well as EF core so that will be the persistence logic. Then we have the API, so that will be the outer layer. And I also have a Blazor application that will be talking with that API. Finally, we have a test folder, which contains several tests.
Soon, we’ll explore this in a lot of detail. I hope you already liking what you see here. As said, I think that for an application such as the one that we’re building for MyTicket, an enterprise application that will have changing requirements overtime, clean architecture is a good choice. One word of warning, though.
Clean architecture can actually be more work, and so I think it is not a perfect fit for every application. It might be overkill for small projects, but remember what happens with small projects? They become large applications before we know it.
In short…
Benefits of clean architecture
- Based on design principles
- Separate concerns
- Create maintainable and testable application code
Entities in the core layer
- Abstractions (high-level)
- Interfaces and entities
- Business logic at the center of the application (use-cases)
- Has no dependencies on external influences
- Independent of UI or used framework
- No knowledge of used database
- Testable and maintainable
How clean architecture born
- Variation on hexagonal and onion architecture
- Introduced in 2012
- Separation of concerns
- Loose coupling
- Independent of “external” influences
- UI
- Databases
Layers and code
- Core (no dependency to any Infrastructure-related code or package)
- Entities
- Interfaces
- Core
- Infrastructure
- Services
- Exceptions
- Infrastructure
- Data access (Entity Framework Core)
- Logging
- Identity
- API clients
- File access
- UI
- API/MVC/Razor
- Specific ASP.NET Core items
- Middleware
- Filters
- Interact with services through MediatR
- Loose coupling
- Lightweight controllers



[…] Architecting ASP.NET Core applications […]
[…] and are an easy solution. Now, while they work, I would advise against using them. First, for the persistence ignorance principle, let’s try not to go away from POCOs for our domain entities. Also, I believe the […]
[…] Architecting ASP.NET Core applications […]
[…] my previous post of Architecting ASP.NET Core applications, in this post I’m going to explain how setting up the application for ASP.NET Core with clean […]
[…] Architecting ASP.NET Core applications […]
[…] Architecting ASP.NET Core applications […]
[…] Architecting ASP.NET Core applications […]
[…] Architecting ASP.NET Core applications […]
[…] registered with the IServiceCollection making it available to classes and components via dependency injection (DI). Blazor uses the same DI container as other ASP.NET Core apps and allows registering of […]